


Pohon keputusan merupakan pemilihan satu alternatif yang
paling optimal dari berbagai alternatif yang tersedia. Secara struktural, pohon
yang dalam analisis pemecahan masalah pengambilan keputusan
adalah pemetaan mengenai alternatif-alternatif pemecahan
masalah yang dapat diambil dari masalah
tersebut. Pohon tersebut juga memperlihatkan faktor-faktor
kemungkinan / probablitas yang akan mempengaruhi alternatif-alternatif
keputusan tersebut, disertai dengan estimasi hasil akhir yang akan didapat bila
kita mengambil alternatif keputusan tersebut. Pohon keputusan juga
dapat digunakan untuk memperhitungkan analisa resiko
dan tingkat utilitas yang ada pada suatu
alternatif pengambilan keputusan. Selain itu, pohon
keputusan juga dapat memperhitungkan nilai dari
informasi tambahan yang mungkin akan kita pergunakan dalam mengambil salah satu
dari alternatif keputusan yang ada di dalam pohon keputusan tersebut.
Prosedur-prosedur untuk melakukan analisis pohon keputusan
antara lain adalah:
1. Membuat pohon (TreeDiagramming)
Pada tahap ini kita harus mengidentifikasi titik keputusan
dan juga titik
kemungkinan
yang mungkin akan terjadi, alternatif untuk setiap titik
keputusan dan juga apa yang mungkin terjadi dari setiap keputusan yang
diambil. Kemudian kita buat sebuah diagram pohon yang
menunjukkan urutan keputusan dan kejadian yang mungkin terjadi.
2. Estimasi kemungkinan (Expected cost = EC)
Pada tahap ini kita harus mengestimasi kemungkinan hasil
dari berbagai kejadian yang mungkin terjadi dan juga konsekuensi keuangan dari
setiap hasil yang mungkin dari berbagai keputusan.
3. Evaluasi dan seleksi
Tahap ini merupakan tahap akhir dimana kita memperhitungkan
nilai yang diharapkan (EMV) dari setiap alternatif keputusan dan memilih
keputusan dengan nilai EMV yang paling besar.
http://wartawarga.gunadarma.ac.id/2010/01/teori-pohon-keputusan/
Data Mining – Konsep
Pohon Keputusan
15
Votes

Pohon Keputusan
Pada sesi ini akan dibahas secara ringkas konsep salah
satu metode data miningyaitu pohon keputusan.
Bahasan meliputi:
- Latar Belakang Pohon Keputusan
- Pengertian Pohon Keputusan
- Manfaat Pohon Keputusan
- Kelebihan Pohon Keputusan
- Kekurangan Pohon Keputusan
- Model Pohon Keputusan
- Algoritman C.45
- Contoh-contoh aplikasi
Latar Belakang Pohon Keputusan
Di dalam kehidupan manusia sehari-hari, manusia selalu
dihadapkan oleh berbagai macam masalah dari berbagai macam
bidang.Masalah-masalah ini yang dihadapi oleh manusia tingkat kesulitan dan
kompleksitasnya sangat bervariasi, mulai dari yang teramat sederhana dengan
sedikit faktor-faktor yang berkaitan dengan masalah tersebut dan perlu
diperhitungkan sampai dengan yang sangat rumit dengan banyak sekali
faktor-faktor turut serta berkaitan dengan masalah tersebut dan perlu untuk
diperhitungkan.Untuk menghadapi masalah-masalah ini, manusia mulai
mengembangkan sebuah sistem yang dapat membantu manusia agar dapat dengan mudah
mampu untuk menyelesaikan masalah-masalah tersebut. Adapun pohon keputusan ini
adalah sebuah jawaban akan sebuah sistem yang manusia kembangkan untuk membantu
mencari dan membuat keputusan untuk masalah-masalah tersebut dan dengan
memperhitungkan berbagai macam factor yang ada di dalam lingkup masalah
tersebut. Dengan pohon keputusan, manusia dapat dengan mudah melihat
mengidentifikasi dan melihat hubungan antara faktor-faktor yang mempengaruhi
suatu masalah dan dapat mencari penyelesaian terbaik dengan memperhitungkan
faktor-faktor tersebut.Pohon keputusan ini juga dapat menganalisa nilai resiko
dan nilai suatu informasi yang terdapat dalam suatu alternatif pemecahan
masalah.Peranan pohon keputusan ini sebagai alat Bantu dalam mengambil
keputusan (decision support tool) telah dikembangkan oleh manusia sejak
perkembangan teori pohon yang dilandaskan pada teori graf.Kegunaan pohon
keputusan yang sangat banyak ini membuatnya telah dimanfaatkan oleh manusia
dalam berbagai macam sistem pengambilan keputusan.
Pengertian Pohon Keputusan
Pohon yang dalam analisis pemecahan masalah pengambilan
keputusan adalah pemetaan mengenai alternatif-alternatif pemecahan masalah yang
dapat diambil dari masalah tersebut. Pohon tersebut juga memperlihatkan
faktor-faktor kemungkinan/probablitas yang akan mempengaruhi
alternatif-alternatif keputusan tersebut, disertai dengan estimasi hasil akhir
yang akan didapat bila kita mengambil alternatif keputusan tersebut.
Manfaat Pohon Keputusan
Pohon keputusan adalah salah satu metode klasifikasi yang
paling populer karena mudah untuk diinterpretasi oleh manusia.Pohon keputusan
adalah model prediksi menggunakan struktur pohon atau struktur
berhirarki.Konsep dari pohon keputusan adalah mengubah data menjadi pohon
keputusan dan aturan-aturan keputusan. Manfaat utama dari penggunaan pohon
keputusan adalah kemampuannya untuk mem-break down proses pengambilan
keputusan yang kompleks menjadi lebih simpel sehingga pengambil keputusan akan
lebih menginterpretasikan solusi dari permasalahan. Pohon Keputusan juga
berguna untuk mengeksplorasi data, menemukan hubungan tersembunyi antara
sejumlah calon variabel input dengan sebuah variabel target.
Pohon keputusan memadukan antara
eksplorasi data dan pemodelan, sehingga sangat bagus sebagai langkah awal dalam proses pemodelan bahkan ketika
dijadikan sebagai model akhir dari beberapa teknik lain. Sering terjadi tawar menawar antara keakuratan
model dengan transparansi model. Dalam beberapa aplikasi, akurasi dari sebuah klasifikasi atau prediksi adalah satu-satunya hal yang ditonjolkan, misalnya sebuah perusahaan direct mail membuat sebuah model yang akurat untuk
memprediksi anggota mana yang berpotensi untuk merespon permintaan, tanpa memperhatikan bagaimana atau mengapa model tersebut bekerja.
eksplorasi data dan pemodelan, sehingga sangat bagus sebagai langkah awal dalam proses pemodelan bahkan ketika
dijadikan sebagai model akhir dari beberapa teknik lain. Sering terjadi tawar menawar antara keakuratan
model dengan transparansi model. Dalam beberapa aplikasi, akurasi dari sebuah klasifikasi atau prediksi adalah satu-satunya hal yang ditonjolkan, misalnya sebuah perusahaan direct mail membuat sebuah model yang akurat untuk
memprediksi anggota mana yang berpotensi untuk merespon permintaan, tanpa memperhatikan bagaimana atau mengapa model tersebut bekerja.
Kelebihan Pohon Keputusan
Kelebihan dari metode pohon keputusan adalah:
- Daerah pengambilan keputusan yang sebelumnya kompleks
dan sangat global, dapat diubah menjadi lebih simpel dan spesifik.
- Eliminasi perhitungan-perhitungan yang tidak
diperlukan, karena ketika menggunakan metode pohon keputusan maka sample
diuji hanya berdasarkan kriteria atau kelas tertentu.
- Fleksibel untuk memilih fitur dari internal node yang
berbeda, fitur yang terpilih akan membedakan suatu kriteria dibandingkan
kriteria yang lain dalam node yang sama. Kefleksibelan metode pohon
keputusan ini meningkatkan kualitas keputusan yang dihasilkan jika
dibandingkan ketika menggunakan metode penghitungan satu tahap yang lebih
konvensional
- Dalam analisis multivariat, dengan kriteria dan kelas
yang jumlahnya sangat banyak, seorang penguji biasanya perlu untuk
mengestimasikan baik itu distribusi dimensi tinggi ataupun parameter
tertentu dari distribusi kelas tersebut. Metode pohon keputusan dapat
menghindari munculnya permasalahan ini dengan menggunakan criteria yang
jumlahnya lebih sedikit pada setiap node internal tanpa banyak mengurangi
kualitas keputusan yang dihasilkan.
Kekurangan Pohon Keputusan
- Terjadi overlap terutama ketika kelas-kelas dan
criteria yang digunakan jumlahnya sangat banyak. Hal tersebut juga dapat
menyebabkan meningkatnya waktu pengambilan keputusan dan jumlah memori
yang diperlukan.
- Pengakumulasian jumlah eror dari setiap tingkat dalam
sebuah pohon keputusan yang besar.
- Kesulitan dalam mendesain pohon keputusan yang optimal.
- Hasil kualitas keputusan yang didapatkan dari metode
pohon keputusan sangat tergantung pada bagaimana pohon tersebut didesain.
Model Pohon Keputusan
Pohon keputusan adalah model prediksi menggunakan struktur
pohon atau struktur berhirarki.Contoh dari pohon keputusan dapat dilihat di
Gambar berikut ini.
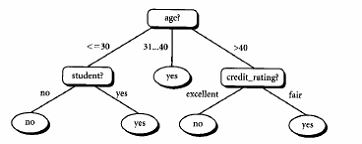
Model Pohon Keputusan (Pramudiono,2008)
Disini setiap percabangan menyatakan kondisi yang harus
dipenuhi dan tiap ujung pohon menyatakan kelas data. Contoh di Gambar 1 adalah
identifikasi pembeli komputer,dari pohon keputusan tersebut diketahui bahwa
salah satu kelompok yang potensial membeli komputer adalah orang yang berusia
di bawah 30 tahun dan juga pelajar. Setelah sebuah pohon keputusan dibangun
maka dapat digunakan untuk mengklasifikasikan record yang belum ada
kelasnya. Dimulai dari node root, menggunakan tes terhadap atribut dari record
yang belum ada kelasnya tersebut lalu mengikuti cabang yang sesuai dengan
hasil dari tes tersebut, yang akan membawa kepada internal node (node
yang memiliki satu cabang masuk dan dua atau lebih cabang yang keluar),
dengan cara harus melakukan tes lagi terhadap atribut atau node daun. Record
yang kelasnya tidak diketahui kemudian diberikan kelas yang sesuai dengan
kelas yang ada pada node daun. Pada pohon keputusan setiap simpul daun
menandai label kelas. Proses dalam pohon keputusan yaitu mengubah bentuk data
(tabel) menjadi model pohon (tree) kemudian mengubah model pohon
tersebut menjadi aturan (rule).
ALGORITMA C4.5
Salah satu algoritma induksi pohon keputusan yaitu ID3
(Iterative Dichotomiser 3).ID3 dikembangkan oleh J. Ross Quinlan. Dalam
prosedur algoritma ID3, input berupa sampel training, label training dan
atribut. Algoritma C4.5 merupakan pengembangan dari ID3.Sedangkan pada
perangkat lunak open source WEKA mempunyai versi sendiri C4.5 yang
dikenal sebagai J48.

Algoritma C4.5
Pohon dibangun dengan cara membagi data secara rekursif
hingga tiap bagian terdiri dari data yang berasal dari kelas yang sama. Bentuk
pemecahan (split) yang digunakan untuk membagi data tergantung dari
jenis atribut yang digunakan dalam split. Algoritma C4.5 dapat menangani
data numerik (kontinyu) dan diskret.Split untuk atribut numerik yaitu
mengurutkan contoh berdasarkan atribut kontiyu A, kemudian membentuk minimum
permulaan (threshold) M dari contoh-contoh yang ada dari kelas mayoritas
pada setiap partisi yang bersebelahan, lalu menggabungkan partisi-partisi yang
bersebelahan tersebut dengan kelas mayoritas yang sama. Split untuk
atribut diskret A mempunyai bentuk value (A) ε X dimana X
⊂domain(A).
Jika suatu set data mempunyai beberapa pengamatan dengan missing
value yaitu record dengan beberapa nilai variabel tidak ada, Jika
jumlah pengamatan terbatas maka atribut dengan missing value dapat
diganti dengan nilai rata-rata dari variabel yang bersangkutan.[Santosa,2007]
Untuk melakukan pemisahan obyek (split) dilakukan tes
terhadap atribut dengan mengukur tingkat ketidakmurnian pada sebuah simpul (node).
Pada algoritma C.45 menggunakan rasio perolehan (gain ratio). Sebelum
menghitung rasio perolehan, perlu menghitung dulu nilai informasi dalam satuan
bits dari suatu kumpulan objek. Cara menghitungnya dilakukan dengan menggunakan
konsep entropi.
S adalah ruang (data) sampel yang
digunakan untuk pelatihan, p+ adalah jumlah yang bersolusi positif atau
mendukung pada data sampel untuk kriteria tertentu dan p- adalah jumlah
yang bersolusi negatif atau tidak mendukung pada data sampel untuk kriteria
tertentu. ntropi(S) sama dengan 0, jika semua contoh pada S berada dalam
kelas yang sama. Entropi(S) sama dengan 1, jika jumlah contoh positif dan
negative dalam S adalah sama. Entropi(S) lebih dari 0 tetapi kurang dari 1,
jika jumlah contoh positif dan negative dalam S tidak sama
[Mitchell,1997].Entropi split yang membagi S dengan n record
menjadi himpunan-himpunan S1 dengan n1 baris dan S2 dengan
n2 baris adalah :
Kemudian menghitung perolehan informasi dari output data
atau variabel dependent y yang dikelompokkan berdasarkan atribut A,
dinotasikan dengan gain (y,A). Perolehan informasi, gain (y,A),
dari atribut A relative terhadap output data y adalah:
nilai (A) adalah semua nilai yang mungkin dari atribut A,
dan yc adalah subset dari y dimana A mempunyai nilai c. Term pertama
dalam persamaan diatas adalah entropy total y dan term kedua
adalah entropy sesudah dilakukan pemisahan data berdasarkan atribut A.
Untuk menghitung rasio perolehan perlu diketahui suatu term
baru yang disebut pemisahan informasi (SplitInfo). Pemisahan informasi
dihitung dengan cara :
bahwaS1 sampai Sc adalah c subset yang
dihasilkan dari pemecahan S dengan menggunakan atribut A yang mempunyai
sebanyak c nilai. Selanjutnya rasio perolehan (gain ratio) dihitung
dengan cara :
Contoh Aplikasi
Credit Risk
Berikut ini merupakan contoh dari salah satu kasus resiko
kredit (credit risk) yang menggunakan decision tree untuk
menentukan apakah seorang potential customer dengan karakteristik saving,
asset dan income tertentu memiliki good credit risk atau bad
credit risk.

Dapat dilihat pada gambar tersebut, bahwa target variable
dari decision tree tersebut atau variable yang akan diprediksi adalah credit
risk dengan menggunakan predictor variable : saving, asset, dan income. Setiap
nilai atribut dari predictor variable akan memiliki cabang menuju predictor variable
selanjutnya, dan seterusnya hingga tidak dapat dipecah dan menuju pada target
variable.
Penentuan apakah diteruskan menuju predictor variable
(decision node) atau menuju target variable (leaf node) tergantung pada
keyakinan (knowledge) apakah potential customer dengan nilai atribut variable
keputusan tertentu memiliki keakuratan nilai target variable 100% atau tidak.
Misalnya pada kasus di atas untuk saving medium, ternyata knowledge yang
dimiliki bahwa untuk seluruh potential customer dengan saving medium memiliki
credit risk yang baik dengan keakuratan 100%. Sedangkan untuk nilai low asset
terdapat kemungkinan good credit risk dan bad credit risk.
Jika tidak terdapat pemisahan lagi yang mungkin dilakukan,
maka algoritma decision tree akan berhenti membentuk decision node yang baru.
Seharusnya setiap branches diakhiri dengan “pure” leaf node, yaitu leaf node
dengan target variable yang bersifat unary untuk setiap records pada node
tersebut, di mana untuk setiap nilai predictor variable yang sama akan memiliki
nilai target variable yang sama. Tetapi, terdapat kemungkinan decision node
memiliki “diverse” atributes, yaitu bersifat non‐unary untuk nilai target
variablenya, di mana untuk setiap record dengan nilai predictor variable yang
sama ternyata memiliki nilai target variable yang berbeda. Kondisi tersebut
menyebabkan tidak dapat dilakukan pencabangan lagi berdasarkan nilai predictor
variable. Sehingga solusinya adalah membentuk leaf node yang disebut “diverse”
leaf node, dengan menyatakan level kepercayaan dari diverse leaf node tersebut.
Misalnya untuk contoh data berikut ini :

Dari training data tersebut kemudian disusunlah alternatif
untuk candidate split, sehingga setiap nilai untuk predictor variable di atas
hanya membentuk 2 cabang, yaitu sebagai berikut:

Kemudian untuk setiap candidate split di atas, dihitung
variabel‐variabel berikut berdasarkan training data yang dimiliki.
Adapun variabel‐variabel tersebut, yaitu :
,di mana

Adapun contoh hasil perhitungannya adalah sebagai berikut :

Dapat dilihat dari contoh perhitungan di atas, bahwa yang
memiliki nilai goodness of split * Φ(s/t) + yang terbesar, yaitu split 4 dengan
nilai 0.64275. Oleh karena itu split 4 lah yang akan digunakan pada root node,
yaitu split dengan : assets = low dengan assets = {medium, high}.
Untuk penentuan pencabangan, dapat dilihat bahwa dengan
assets=low maka didapatkan pure node leaf, yaitu bad risk (untuk record 2 dan
7). Sedangkan untuk assets = {medium, high} masih terdapat 2 nilai, yaitu good
credit risk dan bad credit risk. Sehingga pencabangan untuk assets = {medium,
high} memiliki decision node baru. Adapun pemilihan split yang akan digunakan,
yaitu dengan menyusun perhitungan nilai Φ(s/t) yang baru tanpa melihat split 4,
record 2 dan 7.

Demikian seterusnya hingga akhirnya dibentuk leaf node dan
membentuk decision tree yang utuh (fully grown form) seperti di bawah
ini :
Sistem Pakar Diagnosa Penyakit
(Kusrini)
Dalam aplikasi ini terdapat tabel-tabel sebagai berikut:
- Tabel Rekam_Medis, berisi data asli rekam medis pasien
- Tabel Kasus, beisi data variabel yang dapat
mempengaruhi kesimpulan diagnosis dari pasien-pasien yang ada, misalnya
Jenis Kelamin, Umur, Daerah_Tinggal, Gejala_1 s/d gejala_n, Hasil_Tes_1
s/d Hasi_Tes_n. Selain itu dalam tabel ini juga memiliki field
Hasil_Diagnosis.
- Tabel Aturan, berisi aturan hasil ekstrak dari pohon
keputusan.
Proses akuisisi pengetahuan yang secara biasanya dalam
sistem pakar dilakukan oleh sistem pakar, dalam sistem ini akan dillakukan
dengan urutan proses ditunjukkan pada gambar berikut:

Hasil pembentukan pohon keputusan bisa seperti pohon
keputusan yang tampak pada gambar:
 Lambang bulat pada pohon keputusan
melambangkan sebagai node akar atau cabang (bukan daun) sedangkan kotak
Lambang bulat pada pohon keputusan
melambangkan sebagai node akar atau cabang (bukan daun) sedangkan kotakmelambangkan node daun. Jika pengetahuan yang terbentuk beruka kaidah produksi dengan format:
Jika Premis Maka Konklusi Node-node akar akan menjadi Premis dari aturan sedangkan node daun akan menjadi bagian konklusinya. Dari gambar pohon keputusan pada gambar 4, dapat dibentuk aturan sebagai berikut:
- Jika
Atr_1 = N_1
Dan Atr_2 = N_4
Dan Atr_3 = N_9
Maka H_1 - Jika
Atr_1 = N_1
Dan Atr_2 = N_4
Dan Atr_3 = N_10
Dan Atr_4 = N_11
Maka H_2 - Jika
Atr_1 = N_1
Dan Atr_2 = N_4
Dan Atr_3 = N_10
Dan Atr_4 = N_12
Maka H_2 - Jika
Atr_1 = N_1
Dan Atr_2 = N_5
Maka H_4 - Jika
Atr_1 = N_2
Maka H_5 - Jika
Atr_1 = N_3
Dan Atr_5 = N_6
Maka H_6 - Jika
Atr_1 = N_3
Dan Atr_5 = N_7
Maka H_7 - Jika
Atr_1 = N_3
Dan Atr_5 = N_8
Maka H_8
Model case based reasoning dapat digunakan sebagai metode
akuisisi pengetahuan dalam aplikasi system pakar diagnosis penyakit. Aturan
yagn dihasilkan system ini mampu digunakan untuk mendiagnosis penyakit
didasarkan pada data-data pasien.Dalam penentuan diagnosis penyakit belum
diimplementasikan derajat kepercayaan terhadap hasil diagnosis tersebut.
Referensi:
- Kusrini, Hartati, Penggunaan Penalaran Berbasis
Kasus Untuk Membangun Basis Pengetahuan Dalam Sistem Diagnosis Penyakit
- Teknik Klasifikasi Pohon Keputusan Untuk Memprediksi
Kebangkrutan Bank Berdasarkan Rasio Keuangan Bank
- Pramudiono, Iko. Pengantar Data Mining: Menambang
Permata Pengetahuan di Gunung Data. http://www.ilmukomputer.com
- Kusrini, 2006, Sistem Pakar Teori dan Aplikasi,
Penerbit Andi Offset, Yogyakarta.
- Santosa, Budi. 2007. Data Mining :Teknik Pemanfaatan
Data untuk keperluan Bisnis. Graha Ilmu. Yogyakarta.
- Tan, Pang-Ning, Michael Steinbach, and Vipin Kumar.
2004. Introduction to Data Mining.
- Website WEKA. http://www.cs.waikato.ac.nz/ml/weka/.
- Witten, Ian H. dan Eibe Frank. 2005. Data Mining:
Practical machine learning tools and techniques,2nd Edition.
Morgan Kaufmann. San Francisco.
http://fairuzelsaid.wordpress.com/2009/11/24/data-mining-konsep-pohon-keputusan/
Tidak ada komentar:
Posting Komentar